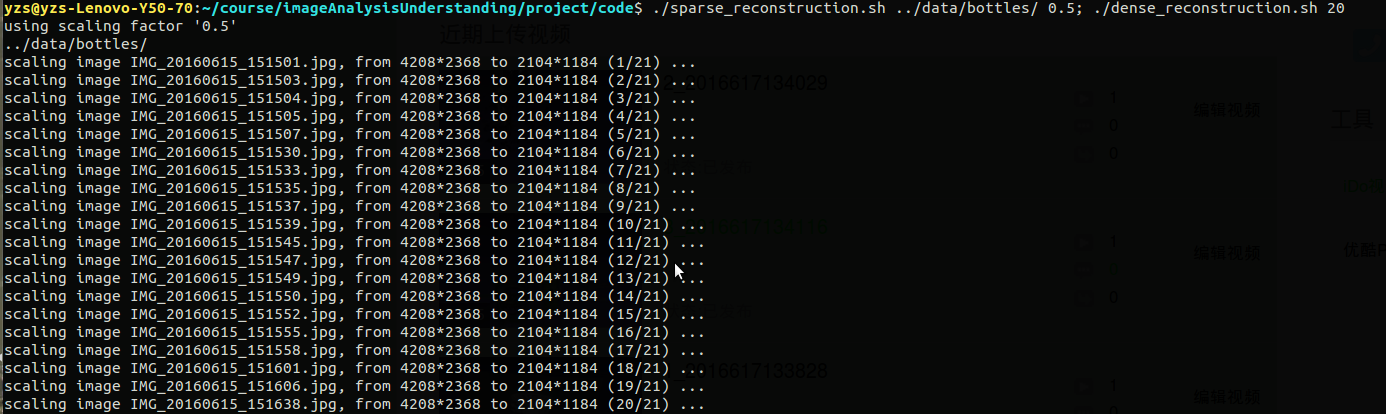
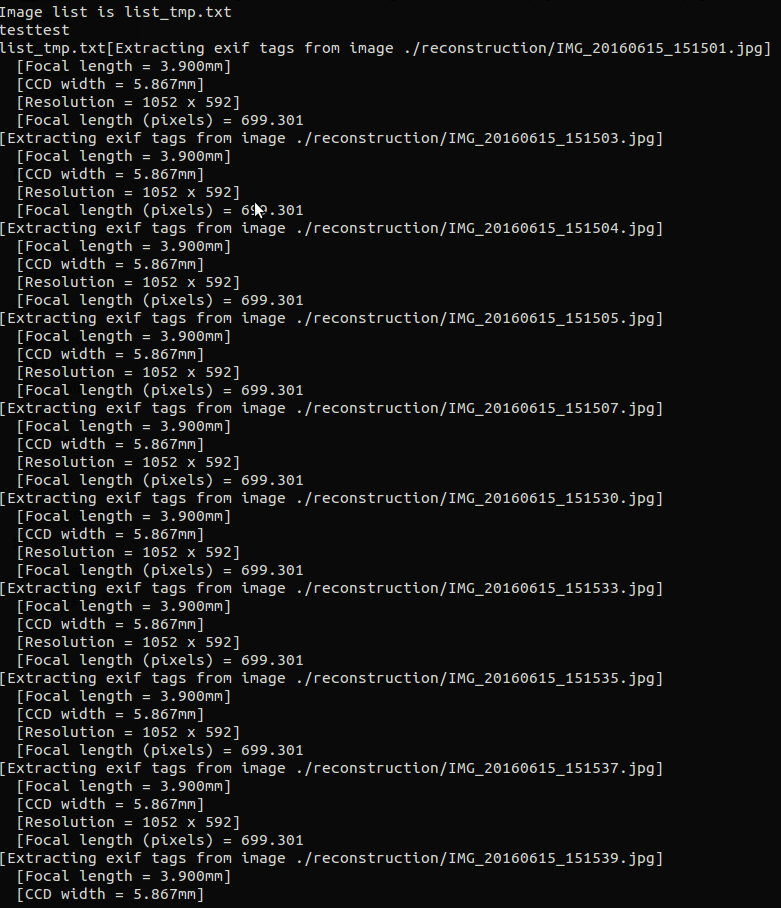
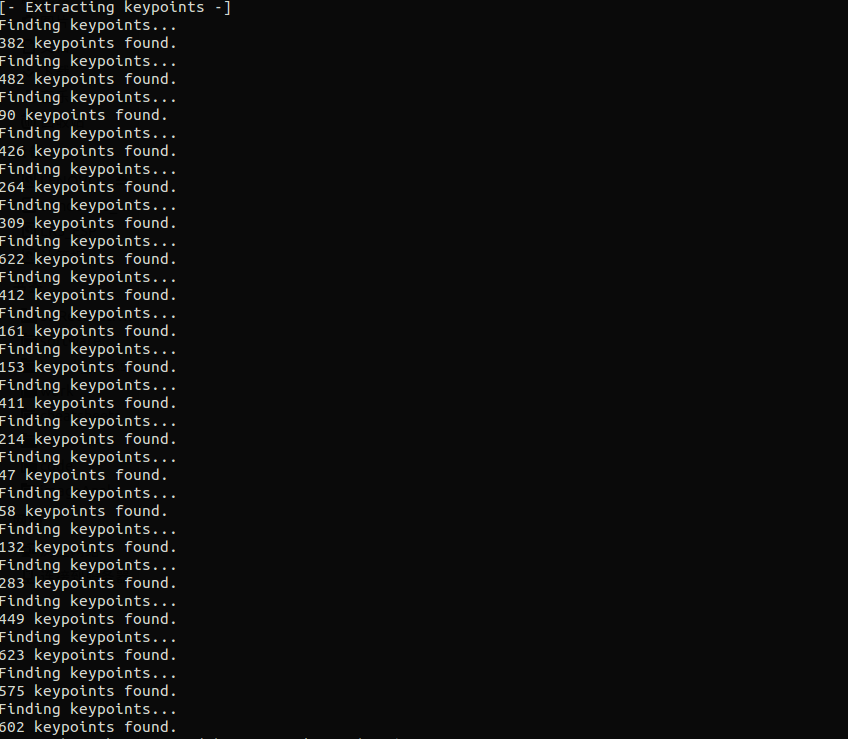
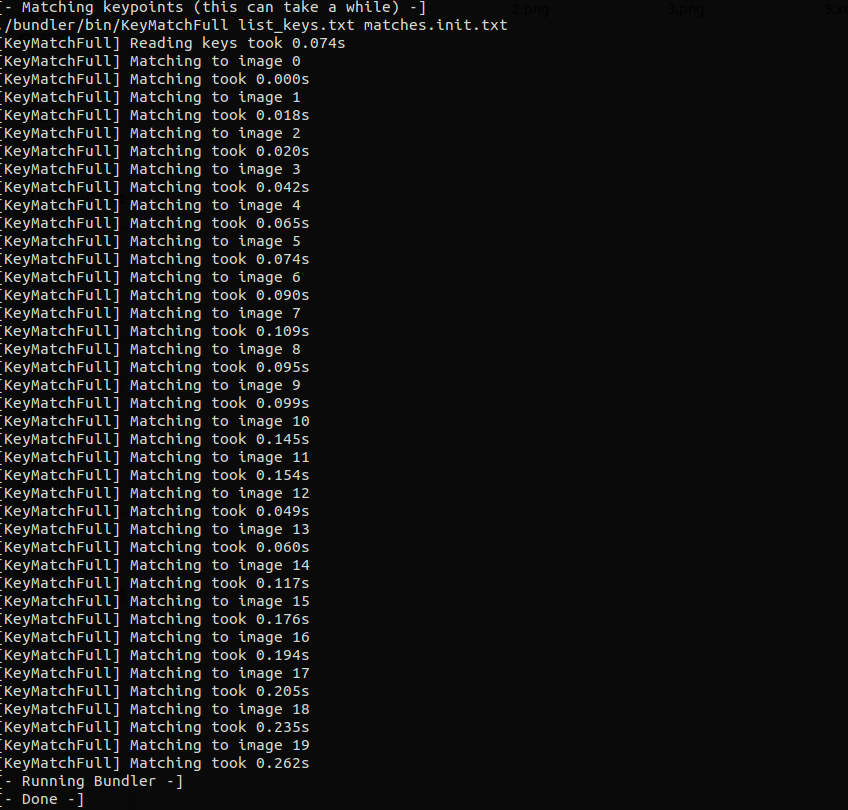
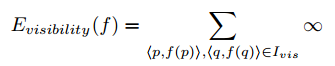3D模型的可视化
Matlab的三维显示系统
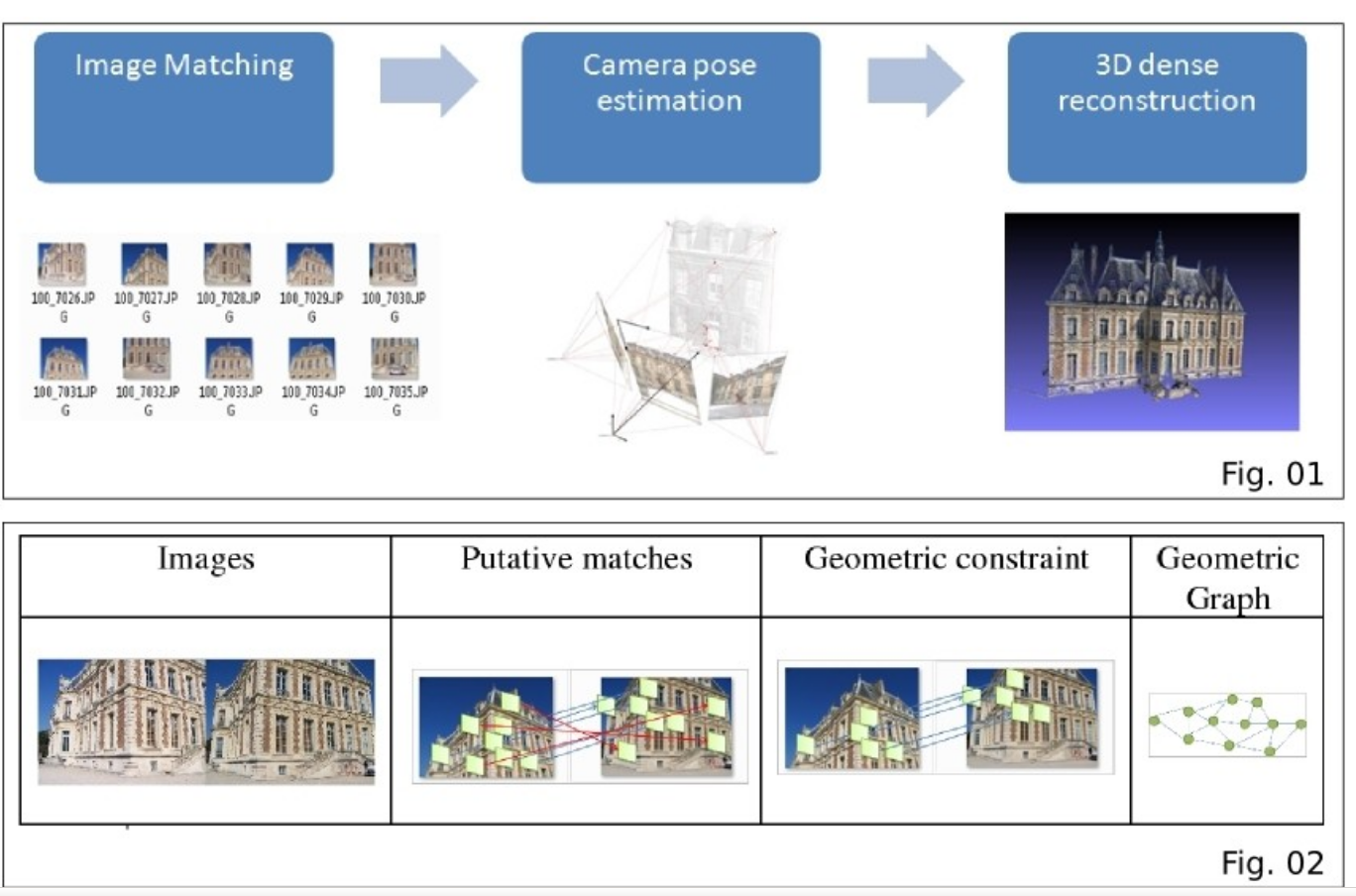
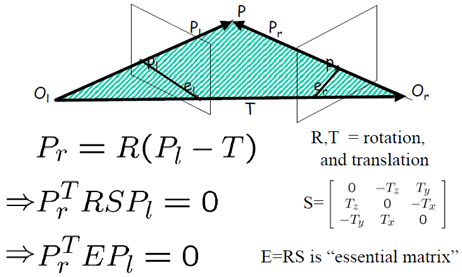
在得到了三维重建的ply模型后,为了便于在PC端显示,我们在matlab下设计了一个显示GUI界面,该界面可以很好的显示ply模型的点云坐标点以及所带的颜色特征。同时为了便于观察设计了四个方向的旋转按钮可以更直观的观察3维信息,主界面如下:
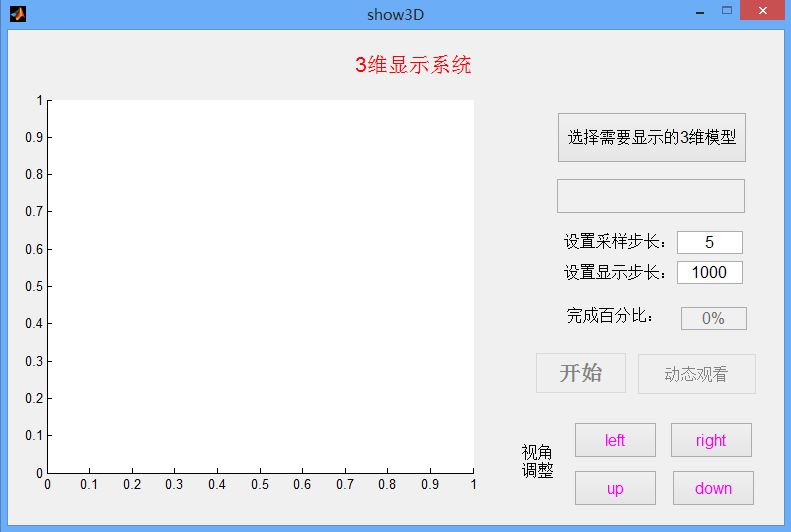
在这里我们可以选择打开一个3维模型,同时为了使得在matlab下显示速度加快,我们设置一个采样步长可以稀疏显示模型的点集,并设置步长显示在界面上。然后开始显示。
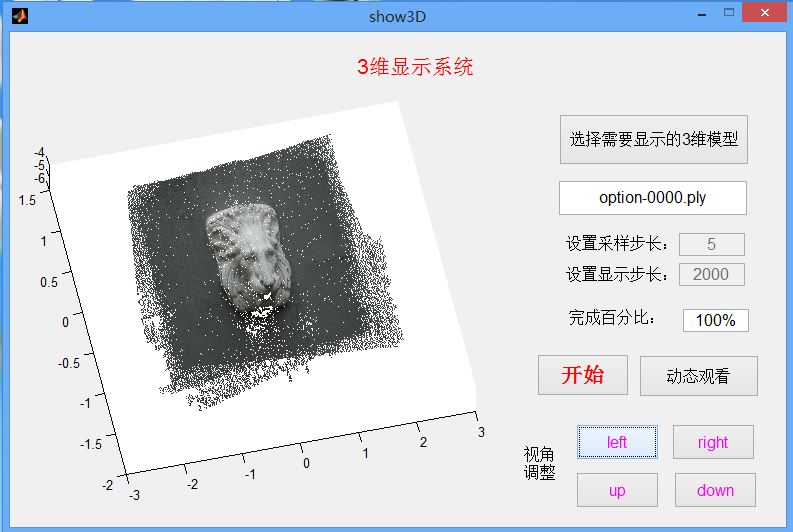
以重建生成的狮子头模型,显示的完成结果如下:
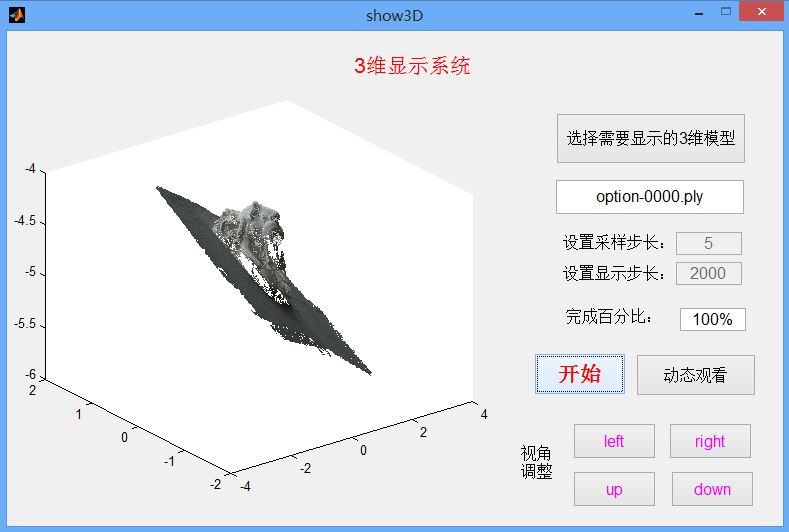
为了在不同视角下观看,可以点击自动的动态观看模式,此时三维模型会自动旋转。同时也可以收手动选择观看角度,一个角度如下:
安卓端三维显示系统
Android 3D Rendering
本次实验要实现的功能是对某一物体多张图片进行3D重新建模。建模部分产生的结果是一个ply文件。安卓端需要在通过对这个ply文件进行解析,然后在手机端屏幕上进行展示。
Android系统使用 OpenGL 的标准接口来支持3D图形功能,android 3D 图形系统也分为 java 框架和本地代码两部分。本地代码主要实现的 OpenGL 接口的库,在 Java 框架层,javax.microedition.khronos.opengles 是 java 标准的 OpenGL 包,android.opengl包提供了 OpenGL 系统和 Android GUI 系统之间的联系。
因此,系统需要先对ply文件进行解析。解析过程分为两个部分。首先是对头部的解析,读取到该文件的中的空间属性个数,颜色属性个数以及面属性个数。然后根据各属性的个数开辟相应数量的空间。第二部分是读取ply文件的数值部分,把相应的数值读取到相应的数组中,这样就完成对ply文件的数据解析。
然后是数据展示部分。在 Android 中我们使用 GLSurfaceView 来显示 OpenGL 视图,该类位于 android.opengl 包里面。它提供了一个专门用于渲染3D 的接口 Renderer.主要需要要实现他的两个方法,onCreated,onDrawFrame。第一个方法是用来在图像初始化的时候使用的,第二个方法用来对图像进项旋转的。通过nio的buffer来保存第一个部分读取到的数据,然后调用GLES20里面的原生方法来使用这些数据对图像进行初始化。旋转的时候,通过记录下旋转矩阵通过旋转矩阵对图像进行重构,达到旋转展示的效果。
同时,为了方便操作,增加了一个reset按钮,当该按钮被点击的时候,重新调用图形的oncreated方法实现图像的重新展示。下面是一个正方体的效果展示。

很遗憾由于最终CMVS生成的.ply文件没有面信息,我们没有在安卓端成功显示自己重建的结果,只能在PC端显示。